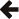


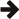
const query<screen> local_screens =
local_cinemas
.jump(screens, screens->cinema_id == local_cinemas->id);
This statement builds on the query local_cinemas,
in much the same way that the previous statement built on the table cinemas.
The effect of jump()
can be understood as follows: imagine we took the output of local_cinemas, and replaced each cinema c by
all the records in screens
whose cinema_id matches
c's id.
That would give us the output of the query we just built. All those records
are of type screen, so
the new query is a query<screen>.
Notice that this operation would work just as well if local_cinemas
were replaced by some other query with the same output as local_cinemas, or even by a simple table
that contained all the records that local_cinemas
produces. And that is generally the way: when I build upon one query to
make another, I try not to depend on any details of how the first query
was built. That makes the code easy to refactor later.
We learnt in the previous section that local_cinemas's
value mapper is identical to cinemas's
value mapper. So I could have written cinemas->... instead
of local_cinemas->....
It would have worked the same, and it would have saved six keystrokes,
but I went the other way. Why? To avoid dependence on the detail of how
local_cinemas was made.
If some future round of refactoring eliminates the cinemas
table, and builds local_cinemas
in some different way, the code here will still compile and run.
I'm expressing a stylistic preference, no more, and it may not be very important -- except insofar is it helps to explain code examples in this document that would be puzzling if you didn't know.