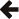


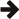
const query<std::string> titles_playing_nearby =
local_screens
.jump(movies, local_screens->current_movie_id == movies->id)
.select(movies->title)
.distinct();
Here we take a query (local_screens)
and call one of its methods (jump()), to produce another query; then call
one of its methods to produce another query; and one
of its methods to produce the query titles_playing_nearby.
It is tempting to read such code as a pipeline, i.e. an instruction to perform the following tasks, either sequentially or in parallel:
local_screens
query. That produces a stream of screen
records.
screen
records by all the records in movies
whose id matches the
screen record's current_movie_id. That produces a
stream of movie records.
movie
records by its title. That produces a stream of std::strings.
std::strings and remove duplicates. That
produces a shorter stream of std::strings.
I find pipeline thinking very useful, and in fact the methods where(),
jump()
etc. have deliberately been made compositional,
so that pipeline thinking works when you chain them together. Still I must
sound a small note of caution: I have no idea whether such pipelines are
real. I don't know whether all the postulated streams and processing stages
actually exist. I know that quince produces SQL queries whose output is
as if produced by a real pipeline, but queries are
executed by the DBMS, and it can use any strategy it likes to get to that
output.